
Introduction to GIS
Within the realm of geographic information systems (GIS), there are two major processes:
- Data collection
- Data management
Data collection
Data collection is the field portion of the work. This involves using remote sensing equipment like:
- Global Positioning System (GPS)
- Unmanned aerial systems (UAS)
- Aerial and mobile LiDAR
- Robotics
- Laser scanning to measure and record data like the size, position, and condition of infrastructure
Data management
Data management, typically referred to as GIS, involves organizing the data into a database that can be queried and rendered visually in tables, graphs, and maps.
While it would seem logical for data collection to precede data management we have to have data in order to organize it there are in fact significant benefits to approaching GIS from the data management side first.
By asking “What do I need to know?” or “What do I want to be able to do?,” we not only establish what fields and functions our database must contain, but also set ourselves up to leverage the tremendous power of the rapidly changing technology in the data collection arena.
What GIS can and cannot do
In order to answer these questions, it helps to understand what GIS can do, and what it cannot do.
GIS is, at its core, simply a vehicle for capturing and displaying large quantities of data, any inaccuracies in its output can be traced back to its input. If the original data is flawed or missing, it will be reflected in the GIS.
GIS does not create inaccuracies. It exposes them.
The reason for poor-quality or absent data is simple: historically, thorough and reliable data acquisition was too costly. High-quality equipment was expensive and the data collection process was labor-intensive. Securing the best equipment was no guarantee of success, however.
For instance, there are measuring devices that advertise the ability to determine the location of a point in space at sub-foot accuracy. In perfect conditions, sub-foot horizontal accuracy can be achieved. The probability of working consistently in that environment is low. In sub-optimal conditions, these devices may be off by many feet. Because each measurement is independent, achieving perfect conditions for one measurement does not guarantee them for the next.
As a result, the recorded data represents varying degrees of inaccuracy, and the presence and degree of inaccuracy may not be readily apparent from the data itself.
How to combat inaccuracies in data

One way of detecting and combating these inaccuracies is recording and understanding metadata. Metadata is data that tells us something about other data. GIS metadata can record information about the accuracy of a measurement using a metric called dilution of precision (DOP). DOP is the relative strength of the satellite configuration used to obtain a GPS reading.
High dilution of precision indicates a high degree of uncertainty, or low accuracy. Low dilution of precision indicates a low degree of uncertainty, or high accuracy.
We can record DOP for horizontal measurements, vertical measurements, or both. With older equipment, the GPS surveyor was responsible for understanding DOP and its impact on data accuracy.
Today, many GPS units translate DOP metadata into an accuracy reading that tells us how far off a point’s recorded location is from its actual location in sub-foot or foot increments.
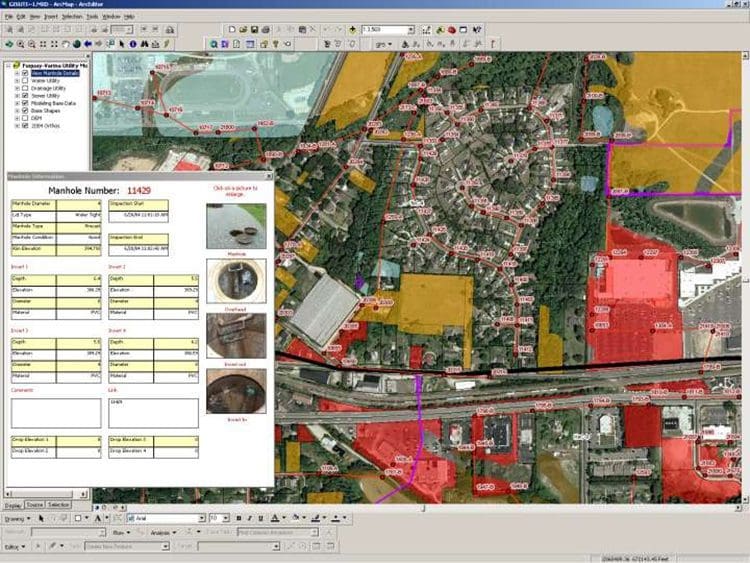
If this metadata is recorded and entered into a GIS database, we can review and evaluate the accuracy of the data for each asset, rather than designating the entire database good or bad when varying degrees of accuracy exist. We can also set thresholds for data accuracy based on how we wish to use the data in a specific instance.
- An asset management plan requires a moderate degree of horizontal accuracy but will be relatively unconcerned with vertical accuracy.
- A hydraulic model absolutely depends on vertical accuracy.
Any data that does not meet the threshold for accuracy for a particular application can be ignored.
The importance of audits
The next step in using GIS (after deciding what we want the data to accomplish) is performing an audit of any data that already exists.
A good audit determines what data is available. It also assesses the quality of that data based on the metadata. Areas where data is missing, and areas where metadata is missing or incomplete, will benefit from a fresh round of field verification or data collection, if needed. The data collection can be performed using all of the improved and new data collection tools at the geomatics professional’s disposal.
Advances in technology
Technological advancements have had a profound effect on modern geospatial data collection.
Data collection in the past versus data collection today is night and day. In the past, the number and location of satellites needed to perform GPS surveying meant that some field work had to take place in the middle of the night. Today, we would have to be in dense canopy not to be able to get enough sufficiently strong satellite signals.
Then, we had to set up our own base station; now, we can hop out of a car nearly anywhere and start surveying . Counties that used to be flown for orthophotography shot in black-and-white at a couple feet per pixel are now shot in color at high resolution.
Unmanned Aircraft Systems (UAS) as a tool

The miniaturization of data collection equipment is a key part of the changing GIS landscape. The camera that can be mounted on a UAS is as powerful as the camera mounted in a plane for orthophotography. This means that entities that used to have to rely solely on county- or state-wide orthophotography for GIS data can now isolate areas of change and use UAS to record, patch together, and orthorectify new data for their databases. The combination of old and new technologies enables more data to be collected quickly, and at a lower cost.

UAS can also be deployed to inspect difficult-to-reach places like water towers, aerial sewers, and the inside of large tanks. Laser scanners, which capture millions of data points in three-dimensional space, are similarly useful in confined spaces like pipes and building interiors.
Both technologies allow us to collect data that was previously challenging to obtain. It’s also safer.
These advancements in data collection drive improvements in data management, which in turn demand further refinements in data collection. As these two processes propel each other forward, the challenge is understanding and manipulating the overwhelming volume of data available.
How do we transform that much data into information?
A solid foundation
Building a solid foundation of GIS data can involve the following:
- Employing sound data management principles like using metadata
- Taking advantage of rapidly improving data collection equipment and techniques
Reliable datasets in place helps inform the decision-making process.
A real-world example
Suppose we have a sewer system, and we know the service life of a specific pipe material is 60 years. So we query the database to find out how many linear feet of this pipe material are in our system, and of those, how many are approaching 60 years old. With this data, we might decide to CCTV those sections of pipe to determine which need to be replaced, and how soon.
During our CCTV inspection, we might discover that some sections of pipe are the same age, but display different degrees of deterioration. What might be the cause? We could review the database to determine what type of soil the pipes are buried in, or whether the pipes are located under pavement that takes a heavy load.
If we have connected our utility database to a work order system, we can look up how and how often the different sections of pipe are maintained. We can even see who inspected the assets, what issues they recorded, and what fixes, if any, were made. We are able to benchmark the performance of maintenance crews at the same time we are benchmarking system performance.
Increasing predictive abilities

Through this process, we can recognize the signs of failure in one area of our system, predict failure in other areas, and move to proactively schedule and budget repairs and replacements. As other utility providers go through this process with their own systems, we can look to each other to increase our respective predictive abilities, particularly when evaluating the success or failure of different material and process changes in different contexts.
But to reach this interconnected and forward-looking place, we have to do a deep assessment of our GIS database. Is it functional? Is it accurate? Are we making good decisions based on our GIS? Are we even using GIS to make decisions?
Once gaps are identified, we can insert data collection and data management technology to fill gaps.